解析Python网络爬虫:核心技术、Scrapy框架、分布式爬虫
”Python Scrapy 爬虫框架 分布式爬虫 设计“ 的搜索结果
本资源提供了一套基于Python的Scrapy爬虫框架与Scrapy-Redis分布式爬虫的设计源码,包含61个文件,其中包括51个Python源代码文件,7个配置文件,以及1个Git忽略文件。此外,还包括1个文本文件和1个Markdown文档。...
本系统采用Scrapy爬虫框架来开发,使用Xpath网页提取技术对下载网页进行内容解析,使用Redis做分布式,使用MongoDB对提取的数据进行存储,使用Django开发可视化界面对爬取的结果进行友好展示,设计并实现了针对链家...
本系统采用Scrapy爬虫框架来开发,使用Xpath网页提取技术对下载网页进行内容解析,使用Redis做分布式,使用MongoDB对提取的数据进行存储,使用Django开发可视化界面对爬取的结果进行友好展示,设计并实现了针对链家...
python scrapy 企业级分布式爬虫开发架构模板 python scrapy 开发企业级分布式爬虫开发架构,使用该架构可快速搭建分布式爬虫环境。 相关技术 使用scrapy_redis进行分布式爬虫操作。 使用mongodb存储数据 开发环境...
程序采用 python 开发的 Scrapy 框架来开发,使用 Xpath 技术对下载的网页进行提取解析,运用 Redis 数据库做分布式, 设计并实现了针对当当图书网的分布式爬虫程序,scrapy-redis是一个基于redis的scrapy组件,...
Python基于Scrapy-Redis分布式爬虫设计毕业源码案例设计 开发环境:Python + Scrapy框架 + redis数据库 程序开发工具: PyCharm 程序采用 python 开发的 Scrapy 框架来开发,使用 Xpath 技术对下载的网页进行提取...
程序采用 python 开发的 Scrapy 框架来开发,使用 Xpath 技术对下载的网页进行提取解析,运用 Redis 数据库做分布式, 设计并实现了针对当当图书网的分布式爬虫程序,scrapy-redis是一个基于redis的scrapy组件,...
本系统采用Scrapy爬虫框架来开发,使用Xpath网页提取技术对下载网页进行内容解析,使用Redis做分布式,使用MongoDB对提取的数据进行存储,使用Django开发可视化界面对爬取的结果进行友好展示,设计并实现了针对链家...
Python基于Scrapy-Redis分布式爬虫设计毕业源码(毕设项目).zip 该项目代码主要针对计算机、自动化等相关专业的学生从业者下载使用,项目代码都经过严格调试,确保可以运行!放心下载使用。 也可作为期末课程设计、...
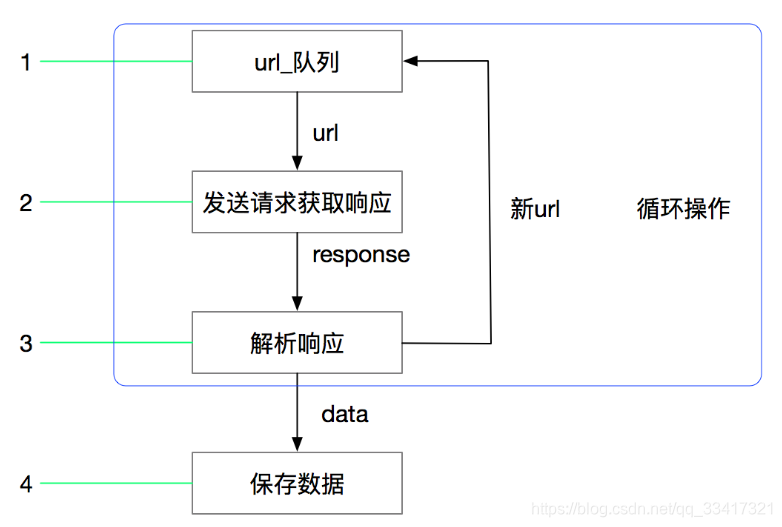
程序采用 python 开发的 Scrapy 框架来开发,使用 Xpath 技术对下载的网页进行提取解析,运用 Redis 数据库做分布式, 设计并实现了针对当当图书网的分布式爬虫程序,scrapy-redis是一个基于redis的scrapy组件,通过...
我们知道,采用scrapy框架抓取网页,我们需要首先给定它一些start_urls,爬虫首先访问start_urls里面的url,再根据我们的具体逻辑,对里面的元素、或者是其他的二级、三级页面进行抓取。而要实现分布式,我们只需要...
所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。对于框架的学习,重点是要学习其框架的特性、各个功能的用法即可。 一、背景 在做爬虫项目...
Scrapy 是一个用于爬取网站数据的强大的开源 Python 框架。它提供了一个高级的抓取和数据提取工具集,使您能够快速、灵活地构建和扩展网络爬虫。强大的功能:Scrapy 提供了一套完整的工具和功能,包括请求调度、数据...

第 一 章:解析python网络爬虫:核心技术、Scrapy框架、分布式爬虫 1-1 初识爬虫 1-1-1 1.1-爬虫产生背景 1-1-2 1.2-什么是网络爬虫 1-1-3 1.3-爬虫的用途 1-1-4 1.4-爬虫分类 1-2 爬虫的实现原理和技术 1-2-1 2.1-...

Python基于Scrapy-Redis分布式爬虫设计毕业源码案例设计 开发环境:Python + Scrapy框架 + redis数据库 程序开发工具: PyCharm 程序采用 python 开发的 Scrapy 框架来开发,使用 Xpath 技术对下载的网页进行提取...
一、说明 虽然scrapy能做的事情很多,但是要做到大规模的分布式应用则捉襟见肘。有能人改变了scrapy的队列调度,将起始的网址从start_urls里分离出来,改为从redis读取,多个...作为一个分布式爬虫,是需要有一个Master
分布式爬虫(scrapy_redis) 分布式爬虫是指将一个大型的爬虫任务分解成多个子任务,由多个爬虫进程或者多台机器同时执行的一种爬虫方式。 在分布式爬虫中,每个爬虫进程或者机器都具有独立的爬取能力,可以独立地...
scrapy提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,是一个为爬取网站数据、提取结构性数据而设计的应用程序框架,它可以应用在广泛领域
scrapy爬虫框架课程,包含全部课件与代码 课程纲要: 1.scrapy的概念作用和工作流程 2.scrapy的入门使用 3.scrapy构造并发送请求 4.scrapy模拟登陆 5.scrapy管道的使用 6.scrapy中间件的使用 7.scrapy_redis概念作用...

BXG-2018-5 8.95GB 高清视频第 一 章:解析python网络爬虫:核心技术、Scrapy框架、分布式爬虫1-1 初识爬虫1-1-1 1.1-爬虫产生背景1-1-2 1.2-什么是网络爬虫1-1-3 1.3-爬虫的用途1-1-4 1.4-爬虫分类1-2 爬虫的实现...
下载地址: Redis 支持 32 位和 64 位。这个需要根据你系统平台的实际情况选择,这里我们下载 Redis-x64-xxx.zip压缩包到 D 盘,解压后,将文件夹重新命名为 redis。 打开一个 cmd 窗口 使用 cd ...分布式:一个业务
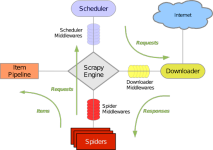
Python爬虫之Scrapy框架系列(23)——分布式爬虫scrapy_redis浅实战【XXTop250部分爬取】
推荐文章
- GPT-ArcGIS数据处理、空间分析、可视化及多案例综合应用
- 在Debian 10上安装MySQL_debian mysql安装-程序员宅基地
- edge 此项内容已下载并添加到 Chrome 中。_一个小扩展,解决Chrome长期以来的大痛点...-程序员宅基地
- vue js 点击按钮为当前获得焦点的输入框输入值_vue获得当前获得焦点的元素-程序员宅基地
- Android 资源文件中@、@android:type、@*、?、@+含义和区别_@android @*android-程序员宅基地
- python中的正则表达式是干嘛的_Python中正则表达式介绍-程序员宅基地
- GeoGeo多线程_geo 多线程-程序员宅基地
- phpstudy的Apache无法启动_phpstudy apache无-程序员宅基地
- 数据泵导出出现ORA-31617错误-程序员宅基地
- java基础巩固-宇宙第一AiYWM:为了维持生计,两年多实验室项目经验之分层总结和其他后端开发好的习惯~整起_java两年经验项目-程序员宅基地